
Construisons des modèles performants. Validons leur fiabilité. Ensemble.
Co-développez vos modèles quantitatifs et d'apprentissage machine avec nos experts et assurez leur robustesse, leur conformité et leur adoption au sein de vos équipes.
Ne laissez pas vos modèles devenir des boîtes noires.
Chaque modèle prédictif a le pouvoir de transformer votre entreprise — ou de l’exposer à des risques invisibles.
En travaillant main dans la main avec vous, nous alignons chaque étape du développement sur vos enjeux d'affaires et réglementaires. Vous gardez le contrôle, vous maximisez l'impact, et surtout, vous favorisez l'adhésion de vos équipes.
Transparence à chaque étape
Conformité aux meilleures pratiques IA (éthique, robustesse, explicabilité)
Montée en compétence de vos équipes internes


Notre méthode : co-construire, valider, transférer
À chaque étape, vous êtes acteurs du processus — et non de simples spectateurs.
Notre méthodologie de co-développement et co-validation couvre l'ensemble du cycle de vie des modèles : de la formalisation du problème d'affaires jusqu’à la mise en production, en passant par les tests de robustesse, la détection de biais et la validation réglementaire (ex : E-23, EU AI Act, ISO/IEC 42001).
Ateliers de co-conception
Formaliser le problème d’affaires et aligner objectifs, hypothèses et données
Co-développement agile
Sprints itératifs pour construire, tester et améliorer vos modèles en continu
Co-validation structurée
Validation rigoureuse de la performance, de la robustesse et de l'équité des modèles

Une approche pensée pour les entreprises exigeantes
Vous développez des modèles critiques pour vos opérations,
Vous devez démontrer la fiabilité et l'équité de vos solutions ML/IA,
Vous voulez accélérer l’adoption de vos modèles en interne,
Vous préparez un audit réglementaire (finance, assurance, santé, etc.).
Nos équipes sécurisent les différentes étapes
du cycle de vie de vos modèles
Définition et cadrage du projet
Définir précisément la problématique à résoudre :
Spécifications fonctionnelles et techniques (définition du problème, objectifs d'affaires, contraintes réglementaires, architecture)
Document d’analyse de faisabilité (évaluation des données disponibles, complexité attendue, valeur potentielle)
Plan initial de gouvernance IA (rôles, responsabilités, processus de validation)

Analyse exploratoire des données (EDA)
Comprendre la nature et la qualité des données disponibles :
Rapport d'exploration des données (outliers, distributions, valeurs manquantes, corrélations)
Dictionnaire de données (description détaillée de chaque variable, sources, types)
Plan de nettoyage et de préparation des données (stratégie pour imputer, filtrer, enrichir les données)
Préparation des données
Transformer les données brutes en données utilisables pour entraîner un modèle :
Pipeline de préparation de données (scripts reproductibles pour la transformation des données)
Rapport de sélection de variables (critères utilisés, variables retenues/éliminées)
Justification des choix de pré-traitement (normalisation, encodage, traitement des déséquilibres)


Conception du modèle
Définir l’architecture du modèle et les stratégies d'entraînement :
Spécifications du modèle (type de modèle choisi, justification, hyperparamètres envisagés)
Plan expérimental d'entraînement (stratégie de validation croisée, métriques d'évaluation définies)
Entraînement et sélection
Former plusieurs modèles et sélectionner le meilleur :
Rapport de performance des modèles (comparaison sur les métriques choisies : accuracy, AUC, RMSE, etc.)
Courbes d'apprentissage (évolution de la performance en fonction des données)
Sélection finale du modèle et justification (choix du modèle retenu et analyse des compromis)

Validation approfondie
Tester la robustesse, la généralisabilité et l'équité du modèle :
Rapport de validation sur jeu de test indépendant (métriques de performance détaillées)
Analyse des biais et équité du modèle (tests de biais démographique, fairness metrics)
Test de robustesse et de sensibilité (analyse des réponses du modèle aux perturbations)
Documentation et explicabilité
Rendre le modèle compréhensible et transparent :
Documentation du modèle (architecture finale, hyperparamètres, dépendances)
Rapport d'explicabilité (SHAP values, règles décisionnelles extraites)
Cartographie du domaine d’application (définir dans quelles conditions le modèle est fiable)


Déploiement en production
Mettre le modèle en service réel, tout en assurant sa traçabilité :
Pipeline de déploiement automatisé (CI/CD) : (scripts pour déploiement reproductible)
Environnement de production documenté (configuration serveur, API, containers)
Plan de monitoring post-déploiement (KPIs à suivre, détection des dérives, alertes)
Monitoring et maintenance
Suivre la performance du modèle sur le long terme et détecter les dérives :
Rapports de performance périodiques
Suivi des métriques clés, alerte en cas de dérive de données ou de concept drift
Plan de révision du modèle (quand et comment réentraîner ou recalibrer le modèle)

Les technologies que nous utilisons au sein de nos projets
Nous adaptons notre stack technologique à vos besoins, à vos contraintes réglementaires et à vos infrastructures existantes (cloud privé, AWS, Azure, GCP, on-premises) pour :
Faciliter la compréhension des données, documenter rapidement les connaissances et assurer la traçabilité dès les premières étapes,
Garantir des pipelines reproductibles, scalables et auditables,
Adapter la solution technique au niveau de complexité nécessaire et optimiser les performances,
S’assurer que les modèles sont performants et responsables (équité, robustesse face aux perturbations),
Rendre les modèles compréhensibles, auditables et renforcer la confiance des utilisateurs finaux,
Permettre des évolutions rapides et sûres du modèle, en limitant les risques de dégradation non détectée.
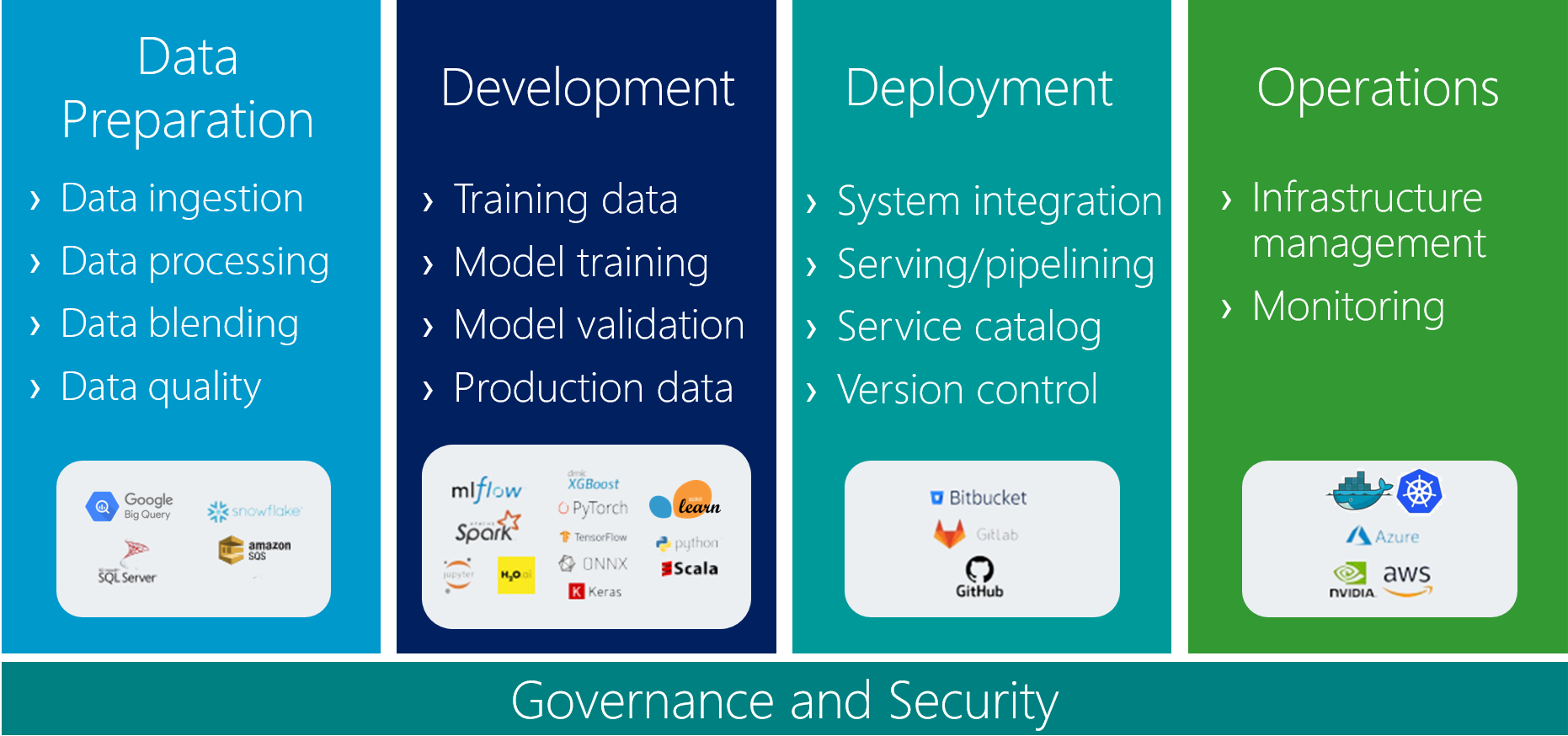
Validation, robustesse et biais
S’assurer que les modèles sont performants et responsables (équité, robustesse face aux perturbations)
Validation statistique : Scikit-learn, Skore, SciPy, Statsmodels
Biais et équité : IBM AI Fairness 360, Fairlearn
Robustesse : ART (Adversarial Robustness Toolbox)
Explicabilité, audit et documentation
Rendre les modèles compréhensibles, auditables et renforcer la confiance des utilisateurs finaux
Interprétabilité locale et globale : SHAP, LIME
Documentation des domaines d'utilisation et validation économique : Insightbounds
Explications contrefactuelles : DiCE (Microsoft)
Ils nous font confiance
Notre expertise est reconnue dans des secteurs exigeants tels que la finance, la santé, l'industrie, les telecoms ou le retail.

Ils ont co-développé avec nous
Ursa Marketing
Création d’audiences marketing basées sur les comportements d’achats,
Multi-touch attribution / modèle d'attribution,
Production des recommandation marketing et mesure d'impacts


Teknion Roy & Breton
Prévision de la demande
Calcul dynamique des niveau des inventaires de sécurité en fonction du niveau de service
Conception d’un modèle hybride combinant approche probabiliste et apprentissage machine
Batimo Développement
Identification des "drivers" du taux d'occupation à 12 mois d'une résidence,
Attribution de performance des investissements marketing utilisés dans les processus d'acquisition de nouveaux clients,
Identification de la propension d'achat d’un prospect.

Pourquoi nous faire confiance à votre tour?
Expertise senior en science des données et validation réglementaire,
Méthodologie reconnue pour nos résultats concrets,
Transfert de compétences à vos équipes,
Engagement total sur la qualité et la conformité.
Exemples de projets réalisés
Lead Scoring
Identifier les prospects qui ont la plus haute probabilité de conversion afin de prioriser les efforts de vos équipe de vente
Segmentation
Définir les segments de clients offrant un potentiel de marché significatif et justifiant une politique marketing distincte
Churn Prediction
Identifier les clients qui vont vous quitter, comprendre les facteurs d’influence et prendre action avant que cela n’arrive
Next Best Offer
Recommander de façon personnalisée des produits et des services pour augmenter vos revenus et l’engagement de vos clients
Demand forecasting
Comprendre et prédire la demande et les ventes afin d'optimiser les décisions de production et d'approvisionnement
Price optimization
Mesurer l'élasticité prix et l'efficacité des promotions, comprendre les comportements d'achats afin de déterminer le meilleur arbitrage entre les quantités vendues et les marges
Mettons vos données au travail
Vous souhaitez sécuriser une importante décision d'affaires ?
Vous souhaitez automatiser une processus critique ?
Vous souhaitez valider une intuition ?
Vous avez besoin d'un second regard ?Un de nos experts peut vous contacter aujourd'hui afin de comprendre votre besoin et organiser un premier appel exploratoire avec vous.
Politique de confidentialité
Dernière mise à jour : 25 Avril 2025
Data Science Institute s’engage à protéger la vie privée de ses prospects et utilisateurs et à respecter les lois applicables en matière de protection des renseignements personnels. Cette politique explique comment nous collectons, utilisons et protégeons vos renseignements personnels dans le cadre de nos services.

1. Collecte des renseignements personnels
Nous collectons vos renseignements personnels uniquement lorsque cela est nécessaire pour fournir nos services, améliorer votre expérience utilisateur ou respecter nos obligations légales. Les types de renseignements que nous collectons incluent, mais ne sont pas limités à :
• Renseignements d'identification : Nom, prénom, adresse courriel, numéro de téléphone, organisation.
• Données d’utilisation : Adresse IP, type de navigateur, préférences, interactions avec nos services.
• Informations financières (le cas échéant) : Identifiants de compte bancaire ou détails de facturation.
2. Finalités de la collecte
Les renseignements personnels sont utilisés pour les finalités suivantes :
• Fournir et personnaliser nos services,
• Gérer les paiements et la facturation,
• Communiquer avec vous concernant nos services,
• Respecter nos obligations légales et réglementaires,
• Améliorer nos produits et services.
3. Consentement
Nous obtenons votre consentement explicite avant de collecter, utiliser ou communiquer vos renseignements personnels, sauf dans les cas prévus par la loi. Vous pouvez retirer votre consentement à tout moment en nous contactant à l’adresse mentionnée ci-dessous. Cependant, cela pourrait limiter votre accès à certains services.
4. Partage des renseignements personnels
Nous ne partageons vos renseignements personnels avec des tiers dans les circonstances suivantes :
• Fournisseurs de services : Partenaires technologiques ou prestataires tiers nécessaires pour fournir nos services (hébergement cloud, opérateur de paiement, plateforme de support technique).
• Obligations légales : Lorsque requis par la loi ou dans le cadre de procédures judiciaires.
5. Sécurité des données
Nous appliquons des mesures de sécurité physiques, administratives et technologiques pour protéger vos renseignements personnels contre tout accès, utilisation ou divulgation non autorisé(e).
En cas d’incident de confidentialité présentant un risque sérieux de préjudice, nous informerons la Commission d’accès à l’information du Québec et les personnes concernées conformément à la loi.
6. Vos droits
Vous avez les droits suivants concernant vos renseignements personnels :
• Accès : Obtenir une copie des renseignements que nous détenons sur vous.
• Rectification : Corriger toute information inexacte ou incomplète.
• Retrait du consentement : Retirer votre consentement à tout moment.
• Suppression : Demander la suppression de vos renseignements personnels, sous réserve des obligations légales.
Pour exercer ces droits, veuillez nous contacter à l’adresse mentionnée dans la section 8.
7. Conservation des renseignements
Nous conservons vos renseignements personnels uniquement pour la durée nécessaire à la réalisation des finalités énoncées dans cette politique, sauf si une période de conservation plus longue est requise ou permise par la loi.
8. Contactez-nous
Pour toute question ou demande liée à la présente politique de confidentialité ou à vos droits, vous pouvez nous contacter :Adresse postale :
DSI Data Science Institute
4 Pl. Ville-Marie Suite 300,
Montreal, Quebec H3B 2E7Adresse courriel : [email protected]
9. Modifications à cette politique
Nous nous réservons le droit de modifier cette politique à tout moment. Toute modification sera affichée sur notre plateforme. Veuillez consulter cette page régulièrement pour vous tenir informé(e) des mises à jour.
Conditions d'utilisation
Dernière mise à jour : 25 Avril 2025
Bienvenue sur le site web Data Science Institute (« le Site »). En accédant ou en utilisant le Site, vous acceptez de vous conformer aux présentes Conditions d’utilisation. Veuillez les lire attentivement. Si vous n’acceptez pas ces conditions, veuillez ne pas utiliser le Site.

1. Acceptation des conditions
En utilisant ce Site, vous confirmez avoir atteint l'âge de la majorité dans votre province de résidence et être légalement capable de conclure un contrat.
2. Utilisation du Site
Vous acceptez d’utiliser le Site uniquement à des fins légales et conformes aux lois en vigueur au Québec et au Canada. Il est interdit de :
• Télécharger, transmettre ou diffuser tout contenu nuisible, illégal, ou offensant.
• Tenter de compromettre la sécurité du Site ou d’en perturber le fonctionnement.
3. Propriété intellectuelle
Tous les contenus du Site (textes, images, logos, vidéos, etc.) sont protégés par des droits d'auteur et appartiennent à Data Science Institute ou sont utilisés avec autorisation.
Il est interdit de reproduire, distribuer ou modifier tout contenu sans autorisation écrite préalable.
4. Confidentialité
L’utilisation de ce Site est également soumise à notre Politique de confidentialité. Nous vous encourageons à la lire pour comprendre comment nous collectons, utilisons et protégeons vos informations personnelles.
5. Liens externes
Notre Site peut contenir des liens vers des sites tiers. Data Science Institute ne contrôle pas ces sites et décline toute responsabilité quant à leur contenu ou à leurs pratiques.
6. Exclusion de garanties
Le Site et ses contenus sont fournis « tels quels », sans aucune garantie explicite ou implicite, notamment quant à leur exactitude ou leur disponibilité en tout temps.
7. Limitation de responsabilité
En aucun cas, Data Science Institute ne pourra être tenue responsable des dommages directs ou indirects découlant de l’utilisation ou de l’incapacité d’utiliser le Site.
8. Modification des conditions
InsightSolver se réserve le droit de modifier ces Conditions d’utilisation à tout moment. Les modifications entreront en vigueur dès leur publication sur le Site. Nous vous encourageons à les consulter régulièrement.
9. Loi applicable et juridiction
Ces Conditions d’utilisation sont régies par les lois de la province de Québec et les lois fédérales applicables du Canada. Tout litige sera soumis à la compétence exclusive des tribunaux de la province de Québec.
10. Contact
Pour toute question concernant ces Conditions d’utilisation, veuillez nous contacter à :Adresse postale :
DSI Data Science Institute
4 Pl. Ville-Marie Suite 300,
Montreal, Quebec H3B 2E7Adresse courriel : [email protected]